
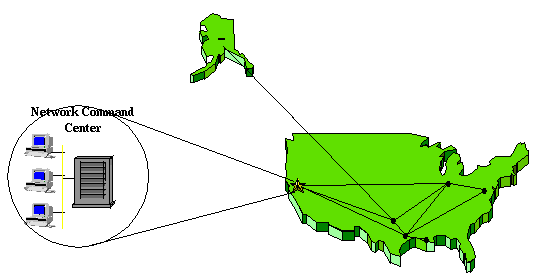
Figure 1
O que é e o que não é.
Por Douglas W. Stevenson
douglas.stevenson@predictive.com 1995 de abril
Sistemas de administração de cadeia especialmente estiveram em operação muitos anos nos próprios mundos proprietário deles/delas como Netview, AT&T Accumaster e o DMA de Corporação de Equipamento Digital. Com o implementação de SNMP, poderiam ser monitorados área local e componentes de cadeia de área largos e " poderiam ser administrados ". Com a quantia vasta de dados crus disponível, a maioria dos Gerentes de MIS não tem nenhuma idéia o que eles realmente querem porque, em parte, eles não sabem o que está disponível. Adicionalmente, como os dados entram em um formato que de fato significa algo? Outros sistemas de comunicações são considerados non-manejáveis porque eles são só acessíveis por um RS-232 porto e não por Netview ou SNMP. Outros tendem a acreditar que Administração de Cadeia significa nada mais que o monitorar e administração de cadeia hardware arquitetônico como Escavadores, pontes e concentrators--nada sobre a capa de cadeia do modelo de OSI é considerado manejável.
O que está alarmando é que a maioria os Engenheiros de Cadeia Sêniors tendem ser resignados para gastar milhares de dólares em hardware e software ANTES DE as reais exigências é juntado e é definido. Departamentos de MIS ou gastam muito pequeno por conseguinte, em administração de cadeia ou eles " vão para sem dinheiro " com as plataformas de hardware enormes e máquinas de inteligência artificiais caras administração de cadeia motriz para a companhia.
No ambiente de hoje de custo que corta e encarecimento de produtividade, implementação de administração de cadeia mais comuns aumentam o número das pessoas exigido apoiar o MIS funciona e estas pessoas novas são engenharia de nível sênior e tipos de apoio; muito caro em a maioria dos casos. Custos típicos estendem nas centenas de milhares de dólares que compram hardware e software para não mencionar o pessoal adicional.
Sistemas de administração de cadeia têm que ser engrenados para o fluxo de trabalho da organização na qual eles serão utilizados. Como cada implementação de MIS é engrenado para as exigências empresariais, assim deva o sistema de administração de cadeia. Se a funcionalidade de administração não faz diretamente ou indiretamente resolva um problema empresarial, é totalmente inútil ao departamento de MIS global e para a companhia.
Administração de cadeia não significa uma aplicação com um banco de dados com algum pedaço grosso enorme de ferro que dirige o espetáculo. Realmente é uma conglomeração integrada de funções que podem estar em uma máquina mas pode medir milhares de milhas, organizações de apoio diferentes e muitas máquinas e bancos de dados. É estas funções que devem ser dirigidas diretamente pelo caso empresarial para cada.
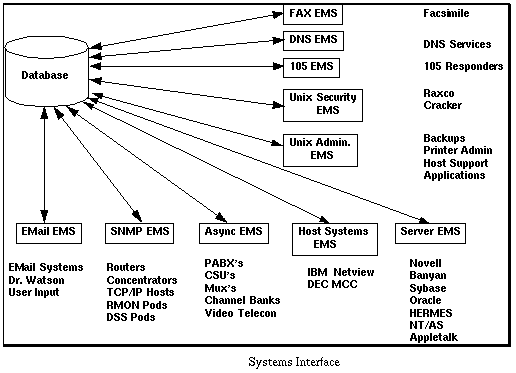
Alguns exemplos de objetos administrados incluem escavadores, concentrators, anfitriões, servidores e aplicações gostam de Oráculo, Microsoft SMS, que Loto Nota, e Correio de MS. O objeto administrado não tem que ser um pedaço de hardware mas deveria ser descrito bastante como uma função provida na cadeia.
O dados atual a ser colecionado vem do objeto administrado, em a maioria dos casos. Este dados é colecionado pelos sistemas de EMS que em troca consolidam os dados em um banco de dados por processar e recuperação.
São traçados estes componentes de sistemas, em troca, atrás ao que é chamado Administração Áreas Funcionais (MFAs). Este MFAs são a lista de desejo de qual áreas em qual aplicações de administração como um enfoque de sistema a atenção deles/delas.
FCAPS é um acronym explicado como segue:
Administração de falta se trata comumente de eventos e armadilhas como eles acontecem na cadeia. Se lembre entretanto de, que usando dados que informam mecanismos para informar alarmes ou alerta são o melhor modo para realizar cheques de saúde do desempenho de objeto administrado específico sem ter que dobrar a quantia de ser apurar votos realizado.
Desempenho de Cadeia de Área Larga (PÁLIDO) vínculos, utilização de tronco de telefone, etc., é áreas que devem ser revisitadas em uma base continuando como estes são algumas das áreas mais fácil de aperfeiçoar e perceber poupanças.
Sistemas ou desempenho de aplicações é outra área na qual podem ser realizados optimization mas a maioria que aplicações de administração de cadeia não enviam para isto de uma maneira funcional.
Como um integrator de sistemas, tenha certeza as exigências são realizadas antes de qualquer implementação. Quando as exigências são postas em lugar, é seu trabalho como um Engenheiro fazer administração segura está informado sobre o que cada segmento de implementação valerá junto com o que aquela capacidade traz à função de MIS global.
O fomentador do caso empresarial tem que olhar o modo atual cada seção realiza seu dia para trabalho de dia. O caso para administração de cadeia pode ser definitized documentando processos de trabalho atuais que podem ser automatizados como um todo pelo sistema. Cada dos processos de trabalho ser automatizado necessidade ser documentado e se dirigiu no desígnio de sistema e implementação.
Procure modos para economizar o dinheiro de organização. Continue enviando adquirindo a organização de MIS e os serviços eles provêem, mais eficiente.
Há os técnicos, engenheiros e pessoal de apoio a cada localização principal como exigido em uma cadeia de local múltipla. Ninguém sabe que esses ambientes locais melhoram que as pessoas que têm que fazer o trabalho. Ninguém conhece melhor que o pessoal de Escrivaninha de Ajuda as pessoas da organização como eles são a primeira linha de comunicação entre as pessoas e o MIS apóie organização.
São considerados elementos de administração de cadeia, entre outras coisas, ferramentas nas quais podem ser realizados troubleshooting. O pessoal de apoio local grandemente poderia beneficiar do uso destes sistemas como uma ferramenta. Como tal, a maioria dos implementação dá acesso somente de leitura a estes sistemas. A habilidade para enfocar estas ferramentas a um nível local é suprema a aumentando a efetividade para o pessoal de apoio local. Em alguns implementação onde acesso de read/write é provido, é realizado por X-Windows que não trabalha muito bem por baixos vínculos de velocidade.
A maioria do enfoque de implementação estas ferramentas a um nível global nisso eles são localizados no Centro de Comando de Cadeia. Quando um ingresso de dificuldade é gerado do NCC, reflete um problema ou sintoma gerou pelo cadeia administração elementos and/or o Gerente de Gerentes. Às vezes, o técnico local não pode relacionar a este sintoma porque ele ou ela não entendem onde esta mensagem veio de ou por que. Sem acesso para o elemento de administração e familiaridade com o produto, eles começam normalmente fora isolamento de problema em uma " nuvem " que procura o problema.
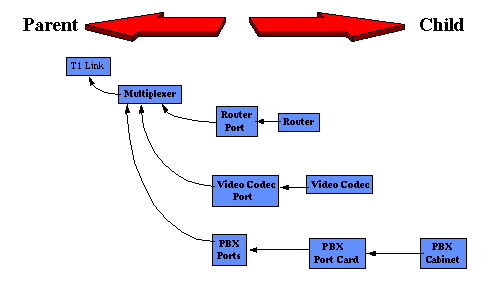
Quando um problema global acontece, nestes enredos, se concentra a informação e é orquestrada pelo Centro de Comando de Cadeia. Adicionalmente um negro de lata de outage fora administração de uma localização geográfica centralizando os recursos de administração. Figure 3 ilustra como isto acontece.
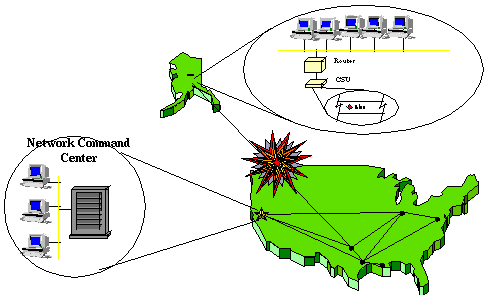
Ajude pessoal de Escrivaninha deveria saber o que está acontecendo e que está trabalhando nisso que à primeira vista. Se eles não estão familiarizados com o sistema em questão, eles deveriam ter informação adequada às pontas do dedo deles/delas os guiar em o que fazer, quem chamar, e que passos para levar, até mesmo que perguntas para perguntar.
Adicionalmente, os problemas que afetam outros locais, deveria estar à primeira vista disponível a esses pessoal. A informação deve estar nas pontas do dedo do pessoal de Escrivaninha de Ajuda dos outros locais de forma que eles saiba, em próximo real tempo, o no qual vai.
Veja como o enfoque de informação deveria ser; local quando é um problema local e global quando é um problema global. Também, são enfocadas as ferramentas associadas mais na situação local e não o quadro global.
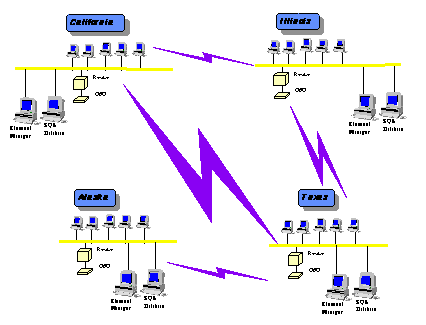
Figure 4 descreve um sistema mais distribuído que proporciona para informação global enfoque local. Neste sistema, podem ser passados alarmes de local para local e até mesmo ao redor de um problema com técnicas de banco de dados de cliente-servidor simples.
Administração de cadeia por baixa velocidade vínculos de área largos realmente não fazem sentido. Bandwidth deste tipo é caro comparou a bandwidth de LAN nisso há as carga de pólvora mensais para os vínculos. Também considere que a maioria dos vínculos PÁLIDOS é interconectado por pontes ou escavadores. No lado de parte de trás destes dispositivos cadeias são capazes de 10 Mbps, 16 Mbps ou até mesmo 100 Mbps. No lado de vínculo você vê 1.544 Mbps, 512kbps ou até mesmo 19.2kbps vínculos. Apurando votos atual de elementos de administração de cadeia (SNMP) poderia consumir estes vínculos que reduzem as capacidades operacionais do vínculo drasticamente. A pergunta para perguntar é você quer há pouco aumentar o bandwidth por estes vínculos para administração de cadeia ou você quer distribuir a administração que apura votos a concentrações de área locais e há pouco passar a real informação de alarme?
O pessoal que deveria estar realizando o trending é as pessoas que realizam o trabalho de fato; novamente ninguém sabe melhor que esses o ambiente pessoal. Necessidades informando ser realizado em um como precisou de base porque cada relatório precisa estar em um formato que o pessoal de apoio local pode entender. Então, cálculos devem estar disponíveis simplificar dados nos relatórios inclusive médias, porcentagens e comparações. Cada tipo de necessidades de relatório para ser customizable e fácil mudar.
Áreas específicas de informar são muito úteis olhando o implementação global. Disponibilidade de cadeia é um método excelente de olhar áreas específicas quando implementou a um baixo nível, i.e., através de objeto. Há vários métodos nos quais isto pode ser realizado de modos que permitem o É pessoal para administrar os recursos efetivamente.
A maioria que relatórios de disponibilidade só se concentram em ver se a caixa está lá para um período de tempo específico e não calculando então atrás o tempo disponível para o número total de unidades de tempo pelo mês. Às vezes são reunidas médias de alguns objetos para produzir uma soma utilizável. A verdade é, a maioria destes tipos de relatórios de disponibilidade não faz nada construtivo mas pacifique administração superior. Se os dados para disponibilidade enfocada ao invés em um weighted importância descrevendo métrica do serviço provida e o que estava acontecendo de fato durante tempo de manutenção, como manutenção marcada, manutenção fora do programa, connectivity perdido devido a qualquer outra coisa que falha, poderiam ser entradas em ação definitivas para evitar alguns dos problemas. Efetivamente, disponibilidade de cadeia é uma ferramenta excelente para içar a bandeira " quando um serviço específico está ficando incerto.
A maioria do uso de implementação uma fórmula de disponibilidade de cadeia semelhante à fórmula mostrada em figura 5. Esta fórmula normalmente é engrenada para dispositivos específicos na cadeia ou a disponibilidade de um tronco. Advertência que o mais dispositivos somaram no cálculo global, o mais obscurecido o cálculo se torna naquele considera todos os dispositivos no mesmo nível como outros e além disso, o mais dispositivos somaram na média global, o mais escondido eles se tornam.
Isto é realizado para cada dispositivo, então calculado a média como um grupo.
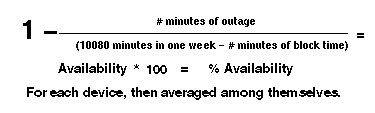
Outro método de realizar disponibilidade é juntar uma lista de serviços, contanto na cadeia, por prioridade. Faça a reportagem da disponibilidade de cada dos serviços em uma base mensal. Use um modificador ou pesagem nesses serviços que são considerados mais importante à organização. Administração reveladora a verdade sobre a disponibilidade de serviços provê uma avenida para corrigir essas coisas que estão tendo problemas e provêem serviços melhores para a comunidade de usuário de fim. Na fórmula figura 6, a pessoa pode ver como podem ser pesados serviços específicos de acordo com importância para as unidades empresariais.
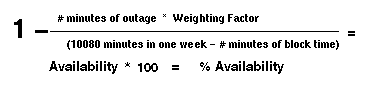
Outro misconception medindo tempo de resposta é o uso de ICMP ping estatísticas. Porque ICMP ecoam que pedidos e respostas estão provavelmente mortas último na prioridade na qual são consertados protocolos em a maioria das caixas, os dados colecionados por pings podem ou pode não ser nenhum dependente preciso em como ocupado o dispositivo estava a tempo naquele momento de particular. Um método muito mais preciso de colecionar dados de tempo de resposta válidos está usando a procuração de Gerente de SunNet ippath " de MIB " ou traceroute usando que estão disponível no domínio público.
Inversamente, a pessoa pode monitorar Fonte de ICMP Extingue para ver se a interface está sendo inundada ou o sistema não pode responder rapidamente bastante para os dados que entram. Este problema específico está comum a Servers de Unix que não tem bastante espaço de troca ou classifica segundo o tamanho para pequeno para os serviços de aplicações que eles provêem.
Alguns dispositivos de RMON podem prover estatísticas no interpacket demore entre dois nodos na cadeia. Isto é especialmente à mão quando monitorando protocolos diferente de IP como o IPX/SPX de Novell.
Escavadores são uma fonte excelente de dados de resposta de eco provida a pessoa ou enlata escritura pelo processo com um anexo de porto de consolo ou por Telnet. Por exemplo, escavadores de Cisco enlatam ping um dispositivo que usa o protocolo de Appletalk.
Há aplicações disponível hoje isso monitorará desempenho de aplicações no Servidor. Estas aplicações provêem uma avenida tipicamente para monitorar um desempenho de aplicações em um servidor e problemas de relatório. Adicionalmente, eles organizam os dados disponíveis associados com as utilizações de recurso atuais de forma que pessoal de sistemas podem persistir o serviço em um nível de desempenho ótimo.
Pode ser medida utilização de cadeia de SNMP fundou objetos administrados que usam o MIB 2 ifinput e mesas de ifoutput de um escavador, ponte ou concentrator. Estes tipos de interfaces normalmente são considerados promíscuos nisso que eles escutam para todos os pacotes embora destino.
RMON Pods usando, a pessoa pode adquirir informação excelente relativo à utilização da cadeia para a que eles são prendidos. Se lembre entretanto, que qualquer dispositivo que executa atravessando ou derrotando vai medidas de utilização de blocos efetivamente sem desdobrar um Pod naquele segmento específico. Estatísticas como tráfico através de protocolo, por endereço de nodo e listas de conexão habilite análise do tráfico no segmento em uma moda muito detalhada.
Enquanto implementando uma medida de tempo de resposta em uma LAN ou PÁLIDO, é muito inteligente conferir a precisão da informação você está juntando. Use um analyzer protocolar bom como uma Cadeia General Expert Sniffer ou H-P LAN Sonda.
Em Cadeias de Área Largas, um pouco de utilizações podem ser realizadas em alguns dispositivos, normalmente só para dispositivos que dynamically alocam bandwidth como exigido. Algum multiplexers de fim alto podem prover estes dados. Interruptores de BANCO 24 HORAS e Cubos definitivamente podem prover normalmente estes dados pelo BANCO 24 HORAS MIB ou por um Empreendimento MIB associou com o próprio dispositivo.
Telefone utilizações de tronco estão disponíveis pela maioria Interruptor e vendedores de PABX embora normalmente usando não SNMP. A maioria tem uma interface terminal que pode ser usada para apurar votos os dados de. Alguns implementação usam um sistema de Contabilidade de Chamada para registrar utilizações detalhadas dos troncos de telefone e estações.
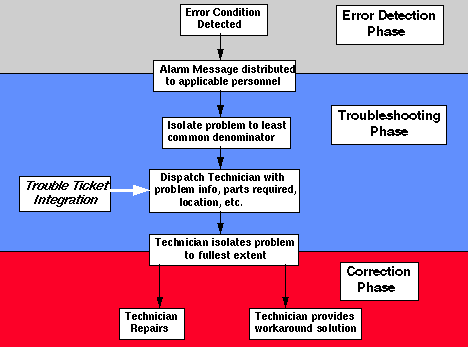
Há terminado esta " Base " de Conhecimento que Tempo Mau para Consertar (MTTR) ciclos se põem mais eficientes. Pense nisto; um problema é descoberto mais rapidamente, uma pessoa de Escrivaninha de Ajuda vê o alarme e começos o processo diagnóstico, então despacha o técnico com bastante informação saber a causa mais provável (que partes para levar!) do problema.
A exibição de alarme atual precisa ser simples e informativo. Enfocando estas mensagens longe de representação vívida, é feita distribuição da informação muito mais simples--e mais rapidamente. Podem ser exibidas até mesmo facilmente mensagens textuais em um VT-100 término discado em um servidor terminal. Outro exemplo é passar alarmes críticos para um pager de exibição, especialmente durante fora horas ou fins de semana.
Correlação de alarme é boa nisso estreita as possibilidades para um denominador comum. Uma vez correlação de alarme é tarefas realizadas, outras podem levar coloque automaticamente como auto-geração de um Ingresso de Dificuldade ou técnico chamar. Até mesmo auto que podem ser iniciados mecanismos curativos uma vez que correlação de alarme aconteceu, i.e., um circuito redundante poderia ser trazido em linha enquanto o vínculo defeituoso sido colocado em auxiliador.
Se verdadeira inteligência artificial será aplicada, a maioria da licença de implementação fora informação significante pertinente a correlação formal. Aplicações de inteligência mais artificiais especificamente se tratam de dois tipos de dados; regras informação baseada e informação de heuristic. Regras informação baseada é aquela informação que pode ser usada para descrever relações de entidade e como essas entidades interagem entre si. Como tal, a maioria das mesas de regras é estático em natureza naquele introduz a informação associada com as relações. O segundo tipo, informação de heuristic, é a informação dinâmica derivada de condições prévias que aconteceram.
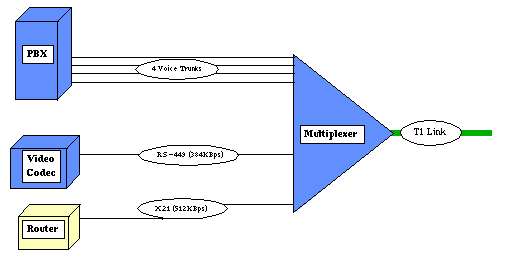
Esta mesma relação pode ser realizada muito em um banco de dados mais simples que a inteligência artificial solução baseada. A inteligência artificial solução baseada proverá um método de calcular, em uma base de porcentagem, a causa mais provável do alarme de raiz. Alarmes de raiz são esses alarmes que de fato têm algo erradamente. Um alarme de efeito colateral é um onde o alarme é causado por um fracasso externo para o objeto administrado. Em figura 5, um fracasso no T1 vínculo informa na verdade alarmes como segue:
Pai Siblings Objeto administrado Endereço Localização etc. T1 vínculo Multiplexer 1 0 XYZ T1 vínculo Multiplexer 2 0 ABC Multiplexer 1 Serial1 Escavador 1 1.1.1.1 XYZ Multiplexer 1 Port5 VC 1 1.1.1.2 XYZ Codec vídeo Multiplexer 1 cartão 25-1 PBX 1 1.1.1.3 XYZ APOGEU PBXProcurando por uma mesa de configuração como o um acima, pode ver você como correlação de alarme fácil realmente é. Construindo estas relações e relacionando uma mesa de alarmes ativos atrás para as relações entre objetos administrados, é relativamente fácil de reduzir um denominador comum. Simplesmente analisando gramaticalmente pela mesa que procura o ponto mais alto no pai - relação de criança se rende o mesmo resultado como a AI conclusão máquina. (Em muito tempo menor mas menos a probabilidade de cálculo de fracasso)
Informação de Heuristic também pode ser derivada contanto acesso alarme ou são providas histórias de sintoma até certo ponto.
Muitos sistemas de administração de cadeia em operação hoje, não faça nada que passar informação para a Escrivaninha de Ajuda - a menos que Criando tipos estejam tripulando a Escrivaninha de Ajuda. Isto é onde estas aplicações realmente perdem o barco nisso que eles foram escritos pelos programadores e engenheiros sem olhar o caso empresarial. Alguns dos programas foram escritos até mesmo por programadores que nunca tiveram que apoiar uma cadeia ou assim parece. O real caso empresarial é que você quer o pessoal de Escrivaninha de Ajuda a ser informado bem e ter informação útil às pontas do dedo deles/delas. Quando o fluxo de processo de trabalho atual é documentado, a pessoa vê facilmente aqueles processos de chave são dirigidos pela Escrivaninha de Ajuda. O mais informado eles são, o menos que tempo é levado adquirindo uma resolução de problema em seu modo a ser realizado. Se eles têm que descobrir o que vai em e se liga de volta o usuário, o tempo ocupado do tempo que um problema foi descoberto ao tempo que um técnico é despachado é aumentado dramaticamente.
A chave global para sucesso na operação de um departamento de MIS é não contratar engenheiros de nível altos caros para realizar o trabalho. São motivadas as pessoas mais quando eles são contratados e são treinados dentro da organização. Isto também é o a maioria valeu efetivo se são distribuídas as perícias da organização a esses conhecimento específico carente nessas áreas. Construindo uma base de conhecimento de sintomas e as tarefas associada com achar e corrigir esses problemas só faz bom senso bom.
Na base de conhecimento, tarefas como cheque certas coisas, chame este técnico ou chame este sujeito ou até mesmo para pedir para perguntas juntar informação, clareiam lugares, às pontas do dedo da pessoa de Escrivaninha de Ajuda, tarefas definitivas para realizar para adquirir os bola rolando.
Pelo processo de eliminação, uma lista de causas prováveis pode ser estreitada só a uma única causa provável olhando um par de coisas e fazendo as perguntas certas.
Construindo esta base de conhecimento e desdobrando isto ao longo da organização, permite pessoal novo a ser dia um produtivo. Além disso, leva o conhecimento de tudo (i.e. Apoio de mesa, Apoio de Servidor, Apoio de Banco de dados, Apoio de Cadeia, Unix Sistemas Apoio, etc.), coleciona aquela informação em um formato de fluxo de processo, e distribui isto para tudo concernidos.
Dados como o número de modelos específicos de discos rígidos ou cartões de vídeo que foram consertados ou foram substituídos durante o último mês, quarto ou ano, permita o Gerente de MIS para urine esses dispositivos que valeram muito para consertar. Análises deste tipo dirigem o custo de manutenção tipicamente abaixo maior que 20%. Por causa do rollover de tecnologia, estas coisas precisam de ser monitoradas em que pode ser mais economicamente possível substituir um computador de mesa inteiro que ter um controlador de disco rígido substituído. Melhor de tudo, os tatos de usuário de fim como se eles estão sendo levados ao cuidado de. Considere isto; o cliente está contente porque o serviço é enfocado para eles e dinheiro é economizado porque vale menos para substituir aquele envelhecimento caixa velha que continuou quebrando.
A habilidade para localizar a carga de trabalho através de departamento é uma ferramenta excelente para administração analisar o número de pessoal por habilidade e ajustando os técnicos à mão para o trabalho. A aplicação de Ingresso de Dificuldade, se integrou com administração de cadeia, provê um fluxo fácil de trabalho e informação localizando problemas de começo para análise depois do fato. O ingresso de dificuldade tem que integrar bem no modo as pessoas realizam trabalho. Enfoque no caso empresarial e o trabalho flui processo.
Alguns aborrecem etiquetando sistemas permite para o técnico conferir inventário para uma parte específica enquanto em linha, gere uma etiqueta durante a noite transportando ou automaticamente sinalize um artigo que é baixo em inventário.
Dificuldade que etiqueta sistemas tem que ter a habilidade para localizar Garantia e informação de administração de manutenção em um fácil usar método. Tantos organizações compram equipamento novo mas não localiza a informação de Garantia até alguém iça a bandeira da que um contrato de manutenção é precisado no tipo específico de dispositivo. Se contratos de manutenção não começam quando garantia termina, podem ser esperadas carga de pólvora adicionais. Tudo estes custos adicionais, tempo perdido adquirindo uma parte mais o adicional 10 a 20% para penalidades de contrato de manutenção, some dinheiro jogado fora.
Um exemplo é um departamento de MIS que teve uma pessoa que passa cinco horas ao redor um dia que confere connectivity de correio eletrônico por Correio de Microsoft e vários portais para outros tipos de sistemas de correio, como SMTP, X.400, Profs, All-in-1, e CC:Mail. Não iria este tipo de problema de fluxo de trabalho sido resolvido facilmente construindo um poller de Correio Eletrônico que enviou para mensagens ecoar caixas postais de tipo pelos vários sistemas. Apurando votos pelos sistemas, poderiam ser conferidos tempo de resposta e connectivity em uma moda automatizada. Se os dados associaram com este sistema foram remetidos e foram analisados gramaticalmente na aplicação de Administração de Cadeia, a pessoa de Apoio de Correio Eletrônica poderia ser livrada até realize outras tarefas associadas com o dele ou o departamento dela. Só se um problema fosse achado, iria a preocupação surja.
Em geral entretanto, estas exigências precisam de ser dirigidas pelo fluxo de trabalho atual processa atualmente em lugar e tentando economizar tempo e dinheiro encurtando estes processos.
Ferramentas de Groupware incluem Esboço de Grupo ou Whiteboarding, conversa de Grupo, Brainstorming, que postit de Grupo nota, grupo que edita e o igual realmente some às pessoas de modos pode interagir. A troca de idéias e informação por departamentos, local e países tendem a adquirir as organizações inteiras que trabalham junto.
Interface de usuário
Figure 10
Não só mensagens de alarme precisam de ser passadas para outro afetado MFD. Alarme informação de correlação e diagnósticos automáticos são exemplos de outra informação relativo para uma falta que provê um quadro melhor do que realmente está acontecendo no outro fim.
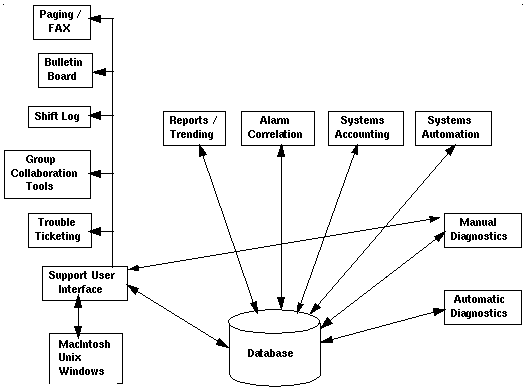
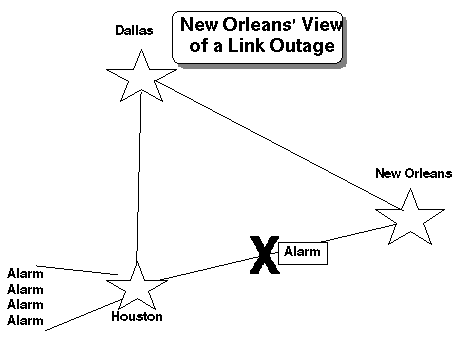
Figure 12
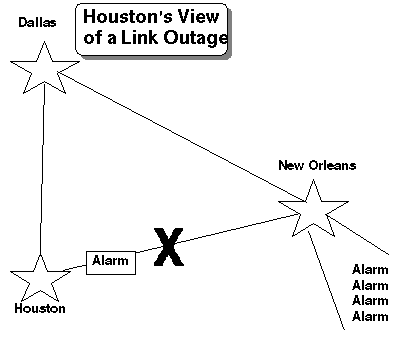
Figure 13
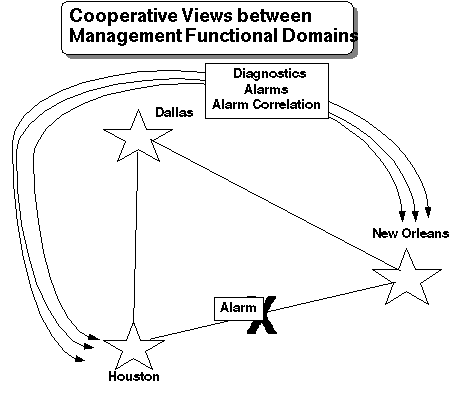
Figure 14
Execute " Corridas " Secas de alarmes e os passos diagnóstico associadas com adquirir o problema na estrada para resolução de uma maneira rápida e eficiente. Tenha as organizações de apoio apropriadas participar de forma que todos os passos diagnóstico pode ser identificado e pode ser incluído. Não omita qualquer notificação de administração que pode ser necessária.
Treine a Escrivaninha de Ajuda para introduzir procedimento de troubleshooting pertinente para a função deles/delas na mesa de diagnósticos. Isto pode incluir qualquer coisa de um usuário que chama com um problema com uma aplicação (i.e. Palavra de MS), para preencher formulários para um serviço específico a ser provido a um usuário de fim.
As habilidades associadas com as organizações de apoio em um MFD podem ser diferentes de outro MFD.
O ajuntamento de procedimentos diagnóstico permite um " compartilhar da riqueza " de conhecimento pelo empreendimento.
Os procedimentos de diagnósticos são uma base de conhecimento de informação, através de sintoma, de problemas e taskings e o que precisa de ser realizado para corrigir o problema.
Tendo as habilidades de Apoio De mesa, Unix Sistema Apoio, Apoio de Cadeia, etc., às pontas do dedo de pessoal de Escrivaninha de Ajuda aumenta a habilidade deles/delas para reagir logicamente a problemas como o deles/delas aconteça.
Sistemas de Administração de elemento, se eles são terceiros produtos de festa como Gerente de SunNet, HP Openview, Netview 6000, Netview, NetMaster, 3M TOPÁZIO, o Integra-T de Larsecom, ou em-casa desenvolveram pollers, precise ser fácil de integrar no sistema inteiro.
Reconheça isso na arquitetura, nenhum EMS está realmente atento de outro.
Consciência pelas necessidades de EMS a ser realizadas a uma capa mais alta de forma que o o enfoque de lata de EMS na área deles/delas de administração dentro do MFD deles/delas.
Funções como Correlação de Alarme, Diagnósticos por EMS, etc., pode ser realizado usando principals de inteligência artificial dentro de um banco de dados de relational.
Quase todos Gerente de produtos de Gerente emprega uma AI Conclusão máquina para calcular a probabilidade aquele componente é tantos por cento mais provável quebrar contra outro.
A inclusão da AI Conclusão Máquina vai de carro o custo por causa da máquina E o ferro correr estes tipos de cálculos.
Estes tipos de necessidade de decisões ser realizado pelas organizações de apoio dentro do MFD porque estes povos sabem melhor que qualquer máquina ou pessoal o ambiente local em outro local.
A aplicação global não serve é pretende melhora se é mais firmemente integrado nas unidades empresariais?
A aplicação de AI ainda precisa de ser aplicada mas a um muito nível diferente.
General de cadeia Distribuiu Servidores de Sniffer são uma aplicação excelente de tecnologia de AI.
Analisando as relações de protocolos, tráfico, conexões e LAN controlam mecanismos.
O DSS usa AI para ordenar problemas a um muito baixo nível antes de eles se tornem o usuário problemas identificáveis e degradação de causa ou tempo de manutenção.
Adicionalmente, pode ser usada inteligência artificial capturar o heuristics de comportamento de cadeia e ajudar com os diagnósticos.
A informação disponível de alarmes passados de problemas semelhantes associados com o que foi realizado isolar e corrigir o problema precisa de ser incorporado no sistema global.
Adicionalmente, porque um sistema de administração de cadeia deve ser customized ao ambiente local, há muitos custos escondidos além do hardware e software.
Olhe o quadro total do empreendimento inteiro e partida o que é proposto ao que é atualmente operacional.
Peça as mesmas perguntas cada local.
Conversão de HTML: Jeff Murphy jcmurphy@acsu.buffalo.edu
Perguntas para Perguntar
Como um Gerente de MIS, quando você é aproximado por pessoal ou vendedores relativo a Administração de Cadeia, há alguns perguntas de chave para perguntar.
Quanto valerá o sistema?
Muitos sistemas implementados hoje são realizados por um Vendedor que especifica o sistema para o Gerente de MIS.
Eles empurram tipicamente à mão quantias enormes de hardware e software aos problemas.
Alguns vendedores lhe falarão até mesmo aquele custo não é importante; é a capacidade que conta.
O sistema proposto integrará em e aumentará meu MIS atual apóiam capacidades?
Muitos Gerentes de MIS realmente perdem o barco não exigindo que o sistema global sido integrado firmemente nas unidades empresariais.
Se os saques de sistemas nenhum propósito empresarial, você que compra tecnologia para a causa de tecnologia...
o sistema é sentenciado a fracasso.
O sistema proposto é modular em desígnio?
Se tudo em um Sistema de Administração de Cadeia está carregado em uma caixa, você está se montando para uso ineficiente de recursos de computação.
Se os contratos de sistemas, a uma caixa será underutilized; se se expande, você estará comerciando aquela caixa em para um maior...
dinheiro perdedor toda vez. O produto é proposto há pouco um Sistema de Administração de Elemento ou é um Integrator de Sistemas de Administração de Elemento?
Muitos vezes, os Gerentes de MIS são vendidos um produto como HP Openview ou IBM Netview 6000 como Gerente de Gerentes System.
Embora, algumas funções de integração são capazes nestes sistemas, você leva longe da habilidade deles/delas para executar real trabalho...
como apurar votos e juntar informação. O que faz o monitor de sistema?
Emparelhe as capacidades do Sistema de Administração de Cadeia proposto para os serviços de I/T chaves providos.
Se não é agora uma partida boa, não será mais recente. O sistema proposto aumenta as capacidades do pessoal de apoio atual ou soma mais pessoal de apoio?
Especialmente tenha cuidado nisso alguns sistemas não farão nada que aumentar suas capacidades de pessoal de apoio atuais e somar cinco ou dez mais pessoal para seu pessoal e para seu orçamento.
Não mencionar, estas pessoas são as especialistas normalmente altamente qualificadas em Administração de Cadeia...
que não vêm baratos.
Conclusão
Há muitos produtos excelentes disponível hoje isso proveja capacidades para não administrar só hardware, mas serviços e aplicações.
O modo que estes sistemas são implementados também é crítico nisso cada capacidade de administração instalada tem que emparelhar uma necessidade empresarial por tal um sistema.
Adicionalmente, estes sistemas diversos devem ser integrados junto e nas organizações de apoio alcançar efetividade de máximo.
Autor: Douglas W. Stevenson